Generative Geostatistical Modeling from Incomplete Well and Imaged Seismic Observations
Creating velocity from field observations.

\[ \newcommand{\pluseq}{\mathrel{+}=} \]
Abstract
Diffusion generative models are powerful frameworks for learning high-dimensional distributions and synthesizing high-fidelity images. However, their efficacy in training predominantly hinges on the availability of complete, high-quality training datasets, a condition that often proves unattainable, particularly in the domain of subsurface velocity-model generation. In this work, we propose to synthesize proxy subsurface velocities from incomplete well and imaged seismic observations by introducing additional corruptions to the observations during the training phase. In this context, proxy velocity models refer to random realizations of subsurface velocities that are close in distribution to the actual subsurface velocities. These proxy models can be used as priors to train neural networks with simulation-based inference. Our approach facilitates the generation of these proxy velocity samples by utilizing available datasets composed merely of seismic images and 5 (for now) wells per seismic image.After training, our foundation generative model permits the generation of velocity samples derived from unseen RTMs without the need of having access to wells.
Methodology
Seismic velocity-model synthesis from incomplete measurements with Generative Geostatistical Modeling (GGM) is an ill-posed problem. In addition, acquiring comprehensive realistic velocity-model training datasets from seismic shot data through the process of full-waveform inversion proves to be too costly. Generative models, particularly diffusion models, offer a solution by training conditional neural networks to synthesize plausible samples, that we refer to as proxy models. After training, these proxy models are synthesized through an iterative denoising process, facilitating high-fidelity, high-dimensional sample generation. Our work leverages generative diffusion models by producing proxy velocity models from limited well-log and imaged seismic information. It negates the need of having access to fully-sampled velocity models during training. Well data provides the only incomplete access to the ground-truth velocities.
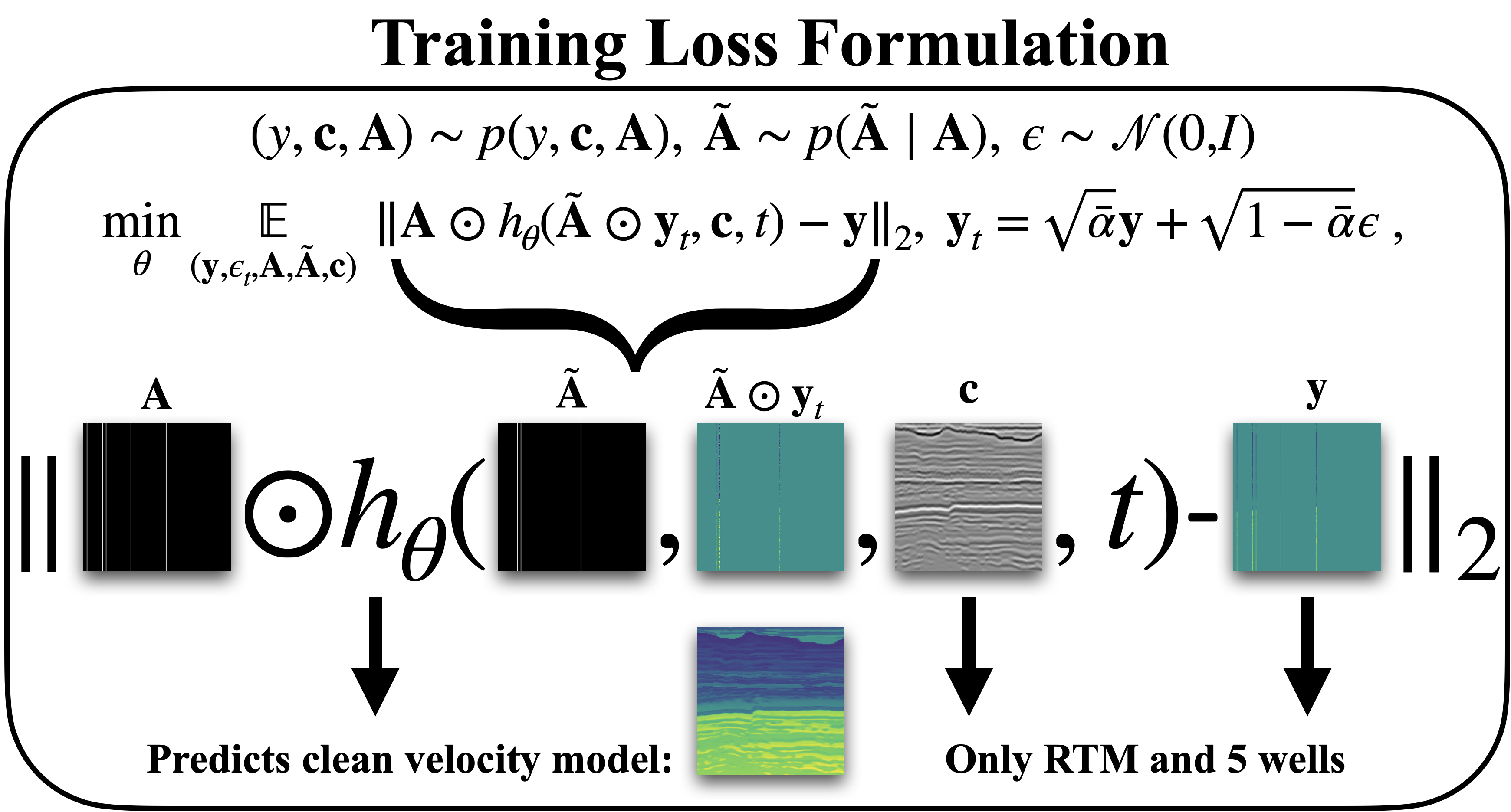
Unfortunately, this lack of fully-sampled velocity models precludes the use of traditional neural reconstruction methods that rely on having access to fully-sampled training examples (Wang, Huang, and Alkhalifah 2024). Inspired by recent work by Giannis Daras and Klivans (2023), Orozco, Louboutin, and Herrmann (2023) and Peters (2020), our study adopts an alternative approach that only requires access to sub-sampled velocity models (i.e. well-log data, denoted by the sub-sampling operator \(\mathbf{A}\)). The sub-sampling corresponds to the action of binary masks with unity columns at locations where well-log data is available. The reconstruction of the fully-sampled proxy velocity models is conditioned on seismic images (denoted by \(\mathbf{c}\)). The proposed training process is illustrated in Figure 1 and repeatedly involves: selection of a 2D seismic image, \(\mathbf{c}\), paired with 5 well logs \(\mathbf{y}\) from which the sub-sampling masks, \(\mathbf{A}\) are generated. Conditioned on this sub-sampling mask, a more sub-sampled mask, \(\mathbf{\widetilde{A}}\) (cf. the masks \(\mathbf{A}\) and \(\mathbf{\widetilde{A}}\) in Figure 1) is generated by zeroing out more columns. Given the action of the more sub-sampled mask on noised and scaled complete well-log data, the neural network is trained to denoise and fit the complete well-log data conditioned on the seismic image. Our network is trained by repeating this process over 20,000 denoising iterations on 2 A100 GPUs involving a training dataset of 3000 training samples.
Results
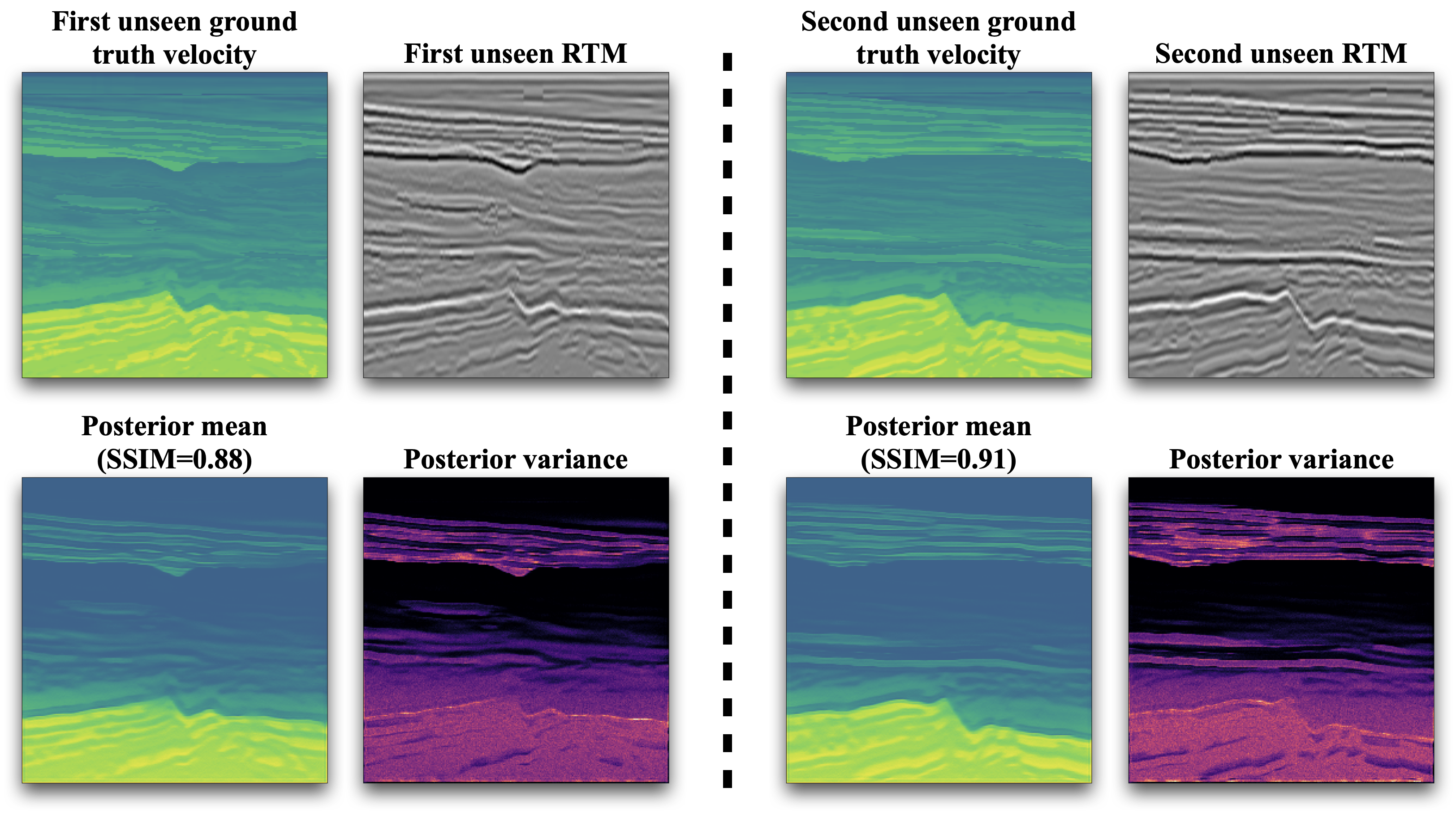
Figure 2 presents results of our generative model for two unseen examples of imaged reflectivities. Given these unseen seismic images (RTMs), our trained neural model synthesizes subsurface velocity models without relying on well data. To validate the quality of our generative samples, comparisons are made between the posterior means (the average of 200 generative samples) and their respective unseen ground-truth test velocity models. These velocity models remained entirely unseen during the training and generative phase. We observe that the posterior means can capture long range structures and produce visually meaningful velocity samples, evidenced by the high Structural Similarity Index (SSIM) scores of 0.88 and 0.91. Furthermore, the conditional posterior variances align closely with particular structures within the velocity models, which underscores the generative model’s capacity to accurately reflect the uncertainty due to two factors: the variability in the subsurface prior information captured from wells seen during training and the uncertainty due to the RTM imaging process. From these results, we conclude that our method conditioned on imaged seismic data is capable of producing high-fidelity samples from the underlying distribution for subsurface velocity models. These samples will serve as input to our full-Waveform variational Inference via Subsurface Extensions (WISE) framework (Yin et al. 2023). Looking ahead, future directions include expanding our dataset across varied geological settings, inclusion of prompts to guide the sample generation, all geared towards advancing on the road to a seismic-based foundation model for subsurface velocities.
Significance
We utilized generative diffusion models to synthesize realistic subsurface velocity model samples. Unlike prior approaches dependent on fully sampled velocity model datasets, our method achieves training with merely \(\approx 2\)% of velocity information derived from well data and corresponding Reverse Time Migrations (RTMs). After training is completed, our model’s sampling mechanism operates without well data, conditioned solely on RTMs to generate velocity samples. The velocity samples produced by our technique are highly beneficial for subsequent tasks such as WISE, which rely on having access to high-fidelity samples of the distribution of subsurface velocity models. Additional material is available at https://slimgroup.github.io/IMAGE2024/.
References
Acknowledgement
This research was carried out with the support of Georgia Research Alliance and partners of the ML4Seismic Center.